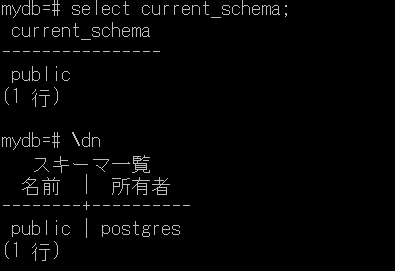
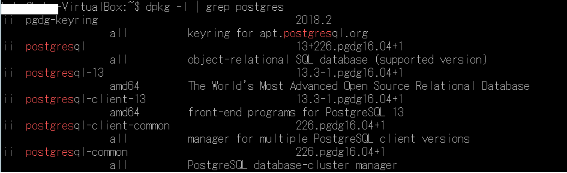
2.動作環境 ここでの実行環境は次の通り。 ・VirtualBox Ubuntu 16.04.7 LTS ・sedのバージョン $ sed –version sed (GNU sed) 4.2.2 Copyright (C) 2012 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later http://gnu.org/licenses/gpl.html. This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. :
3.sedの基本 3.1 sedの基本構文 (1)sedコマンドの書式 sed [オプション ・・・] ファイル名 [ファイル名2 ・・・] sed [-v] [–version] [-h] [–help] ・sedの主なオプション -e スクリプト 処理内容を指定 d 削除する s 指定したパターンに対して置換を行う g すべて置換する w 編集結果を別ファイルに保存する y 文字の置き換え・圧縮する -f ファイル名 指定したスクリプトファイルからコマンドを読み込む -V, –version バージョン情報を表示 -h, –help ヘルプ -E,-r 拡張正規表現を使う -i, 標準出力せずにファイルを上書き
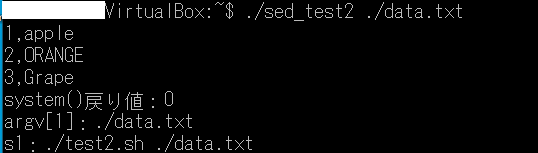
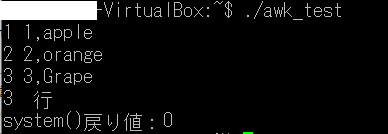
・置換した結果をパイプでファイルに出力 $ sed -e “s/apple/APPLE/” data.txt > data_new.txt $ vi data_new.txt 1,APPLE 2,orange 3,Grape ※この場合は処理部分を”(ダブルクォーテーション)で囲まなくても同じ結果が得られるが、”s/apple/A P P L E/”などスペースを使うときは”(ダブルクォーテーション)で囲まないと正しく処理されない。 (2)削除 ・3行目を削除する $ sed -e 3d data.txt 1,apple 2,orange (3)置換してファイル上書き $ sed -i s/orange/ORANGE/ data.txt $ vi data.txt 1,apple 2,ORANGE 3,Grape
3.3 スクリプトファイルから読む sample2.sed
s/orange/ORANGE/
$ sed -f sample2.sed data.txt 1,apple 2,ORANGE 3,Grape
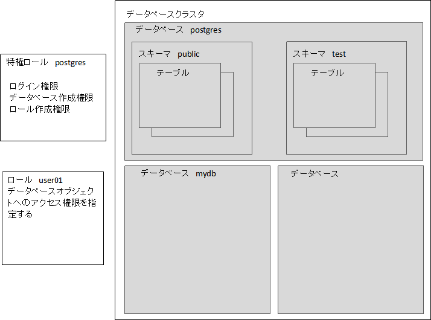
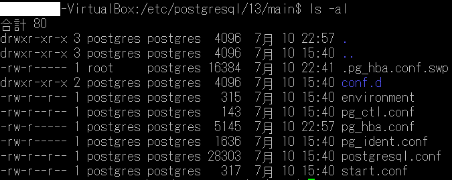
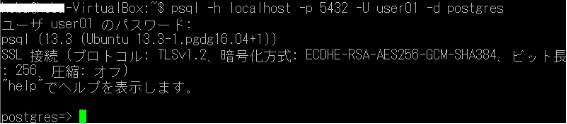
(1)スーパーユーザpostgresでpsqlを起動して、postgresのDBにログインする $ psql -U postgres -d postgres (2)ロール(user01)を作成する postgres=# CREATE ROLE user01; (3)ログイン権限を与える postgres=# ALTER ROLE user01 LOGIN; (4)パスワードを設定する postgres=# ALTER ROLE user01 PASSWORD ‘1212’; (5)ロールuser01でデータベースにアクセスする postgres@*-VirtualBox:~$ psql -U user01 -d postgres psql: エラー: FATAL: ユーザ”user01″で対向(peer)認証に失敗しました ※peer認証とは PostgreSQL内のユーザーとUNIXユーザで、ユーザー名が一致していれば認証情報なしでログインできる仕組みで、psql側でユーザーを作るときには同名のUNIXユーザーも追加する必要がある。ここでは、テスト用として認証方法を変更して進める。 pg_hba.confファイル PostgreSQLに接続するクライアントの認証に関する設定を記述するファイル $ cd /etc/postgresql/13/main $ ls -al
/etc/postgresql/13/main# vi pg_hba.conf
(変更前)
# Database administrative login by Unix domain socket
local all postgres peer
# "local" is for Unix domain socket connections only
local all all peer
※認証方式
trust:任意のロール名でパスワードなしで接続可能
md5:パスワード認証
peer:Peer認証
peerをtrustに変更
(変更後)
# Database administrative login by Unix domain socket
local all postgres trust
# "local" is for Unix domain socket connections only
local all all trust
~/Prolog$ swipl test.pl
Welcome to SWI-Prolog (Multi-threaded, 64 bits, Version 7.2.3)
Copyright (c) 1990-2015 University of Amsterdam, VU Amsterdam
SWI-Prolog comes with ABSOLUTELY NO WARRANTY. This is free software,
and you are welcome to redistribute it under certain conditions.
Please visit http://www.swi-prolog.org for details.
For help, use ?- help(Topic). or ?- apropos(Word).
?- mortal(socrates).
true.
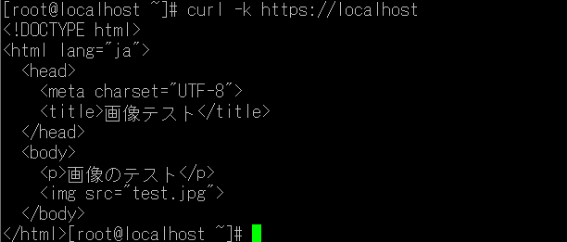
・サーバ証明書の作成 CSRファイル(認証局にサーバ証明書を発行してもらう時に使用するファイル)を作成 # openssl req -new -key server.key > server.csr 下記はEnterでテストでは入力無しとした : Country Name (2 letter code) [XX]: State or Province Name (full name) []: Locality Name (eg, city) [Default City]: Organization Name (eg, company) [Default Company Ltd]: Organizational Unit Name (eg, section) []: Common Name (eg, your name or your server’s hostname) []: Email Address []: Please enter the following ‘extra’ attributes to be sent with your certificate request A challenge password []: An optional company name []: ・サーバ証明書への署名 本来はこのCSRファイルを認証局に渡して署名してもらう必要があるが、ここではテストのため、自分で署名するため、以下のコマンドを実行。 # openssl x509 -req -signkey server.key < server.csr > server.crt