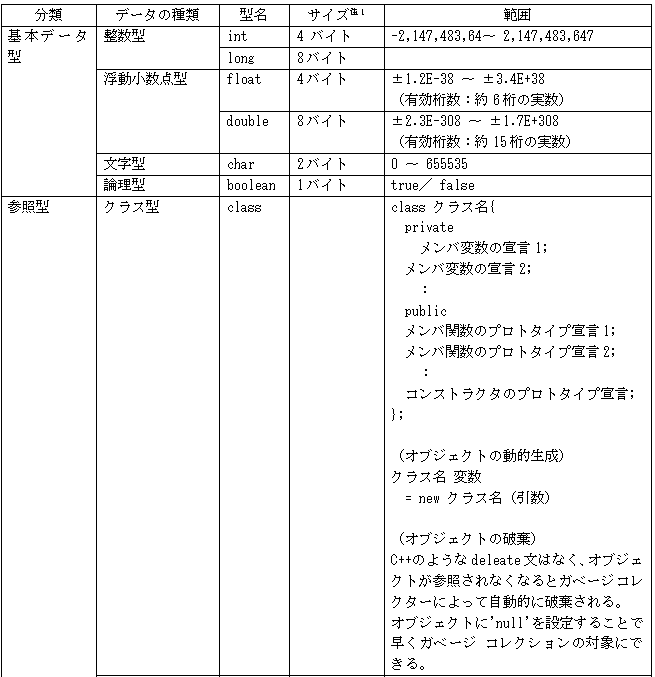
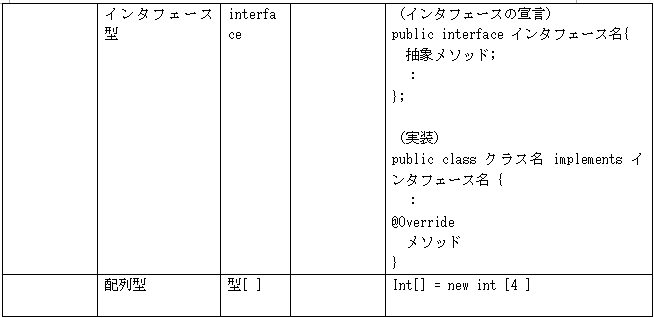
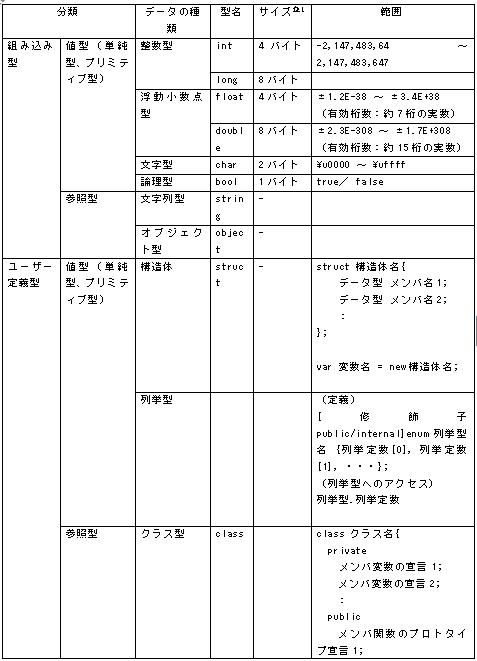
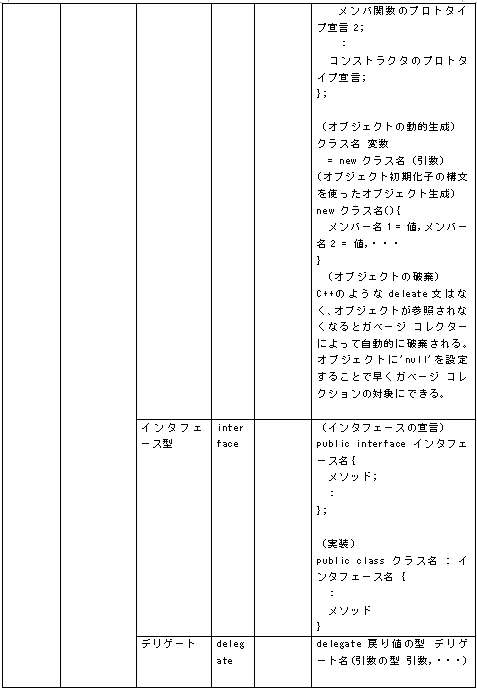
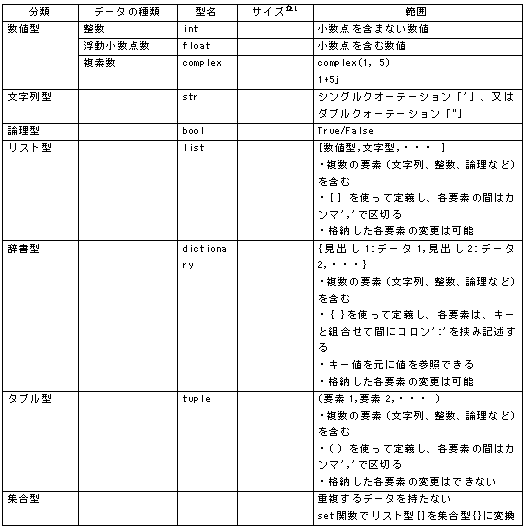
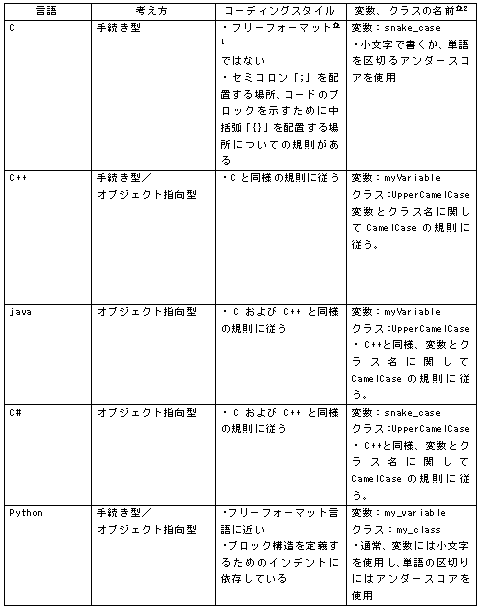
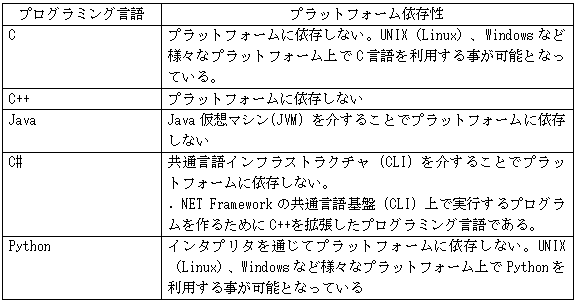
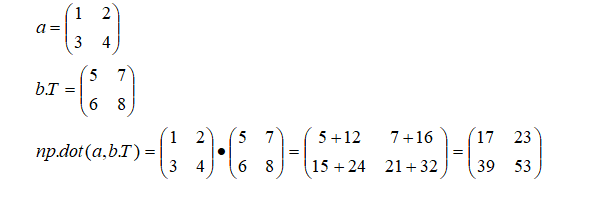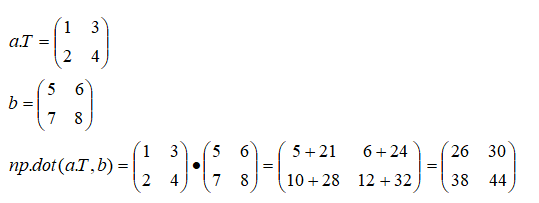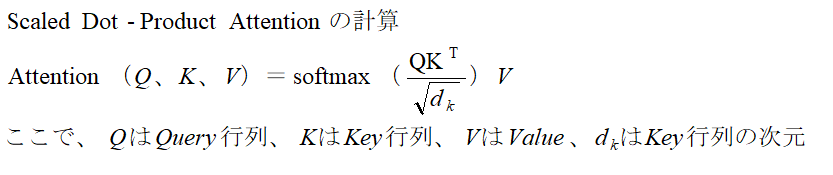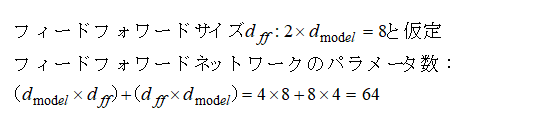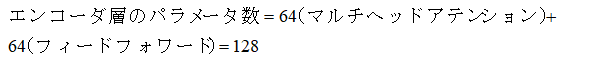1.言語の仕様 ①CとC++ C17 C言語の標準規格ISO/IEC 9899:2018 C++20 C++ の標準規格 ISO/IEC 14882:2020 ②java 主にJava Community Process (JCP) によって決定される。JCP は、Java言語仕様、Java仮想マシン (JVM) 仕様、Java Standard Edition (Java SE) APIなどのJava標準の開発を監督するコミュニティ主導の組織 仕様は、JSRs(Java Specification Requests)に記述されています (参考) List of all JSRs https://www.jcp.org/en/jsr/all
③C# ECMA-334(Ecma International、以前の欧州電子計算機工業会) ISO/IEC 23270 JIS X 3015 (参考) バージョン7.0 ECMA-334:2023 (2023年12月) ISO/IEC 20619:2023 (2023年9月) リリース時期2017年3月 .NET Framework 4.7 Visual Studio2017 version 15.0 https://ja.wikipedia.org/wiki/C_Sharp
#include <stdio.h>
#include <stdlib.h>
int main() {
int *heap_var = (int*)malloc(sizeof(int));
if (heap_var != NULL) {
printf("Address of heap_var: %p\n", (void*)heap_var);
free(heap_var);
}
return 0;
}
#実行結果
koba@koba-VirtualBox:~/work$ gcc c_memo4.c
koba@koba-VirtualBox:~/work$ ./a.out
Address of heap_var: 0x55dc2abee2a0
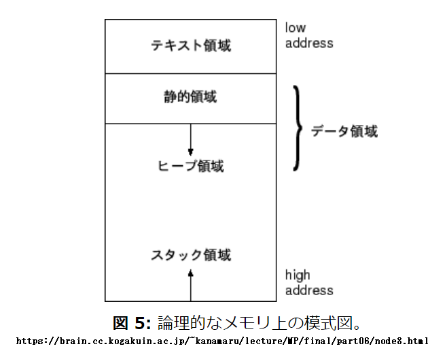
各種類の領域をまとめて表示
#include <stdio.h>
#include <stdlib.h>
// グローバル変数
int global_var = 0;
static int static_var = 0;
void dummy_function() {}
int main() {
// ローカル変数
int local_var = 0;
// ヒープ変数
int *heap_var = (int*)malloc(sizeof(int));
if (heap_var == NULL) {
fprintf(stderr, "Memory allocation failed\n");
return 1;
}
// 各メモリ領域のアドレスを表示
printf("Address of main: %p (Text Segment)\n", (void*)main);
printf("Address of dummy_function: %p (Text Segment)\n", (void*)dummy_function);
printf("Address of global_var: %p (Static Segment)\n", (void*)&global_var);
printf("Address of static_var: %p (Static Segment)\n", (void*)&static_var);
printf("Address of local_var: %p (Stack Segment)\n", (void*)&local_var);
printf("Address of heap_var: %p (Heap Segment)\n", (void*)heap_var);
// メモリ解放
free(heap_var);
return 0;
}
#実行結果
koba@koba-VirtualBox:~/work$ gcc c_memo5.c
koba@koba-VirtualBox:~/work$ ./a.out
Address of main: 0x5629cd6bd1d4 (Text Segment)
Address of dummy_function: 0x5629cd6bd1c9 (Text Segment)
Address of global_var: 0x5629cd6c002c (Static Segment)
Address of static_var: 0x5629cd6c0030 (Static Segment)
Address of local_var: 0x7ffd969119dc (Stack Segment)
Address of heap_var: 0x5629cd9c82a0 (Heap Segment)
Address of main : 0x5629cd6bd1d4 (Text Segment) テキスト領域 low address
Address of dummy_function : 0x5629cd6bd1c9 (Text Segment) 〃
Address of global_var : 0x5629cd6c002c (Static Segment) 静的領域
Address of static_var : 0x5629cd6c0030 (Static Segment) 〃
Address of heap_var : 0x5629cd9c82a0 (Heap Segment) ヒープ領域
Address of local_var: 0x7ffd969119dc (Stack Segment) スタック領域 high address
2.スタックメモリの確認方法 (1)GDB (GNU Debugger)の使用
#include <stdio.h>
void func2(int x) {
int y = x + 2;
printf("func2: y = %d\n", y);
}
void func1(int a, int b) {
int c = a + b;
func2(c);
}
int main() {
int p = 5;
int q = 10;
func1(p, q);
return 0;
}
#デバッカgdbで実行
// -gオプションを付けてコンパイル
koba@koba-VirtualBox:~/work$ gcc -g c_gdb.c
// gdbデバッカの起動
koba@koba-VirtualBox:~/work$ gdb ./a.out
GNU gdb (Ubuntu 9.2-0ubuntu1~20.04.1) 9.2
Copyright (C) 2020 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from ./a.out...
(gdb) i b
No breakpoints or watchpoints.
// ブレークポイントの設定
(gdb) break main
Breakpoint 1 at 0x11a4: file c_gdb.c, line 13.
(gdb) break func2
Breakpoint 2 at 0x1149: file c_gdb.c, line 3.
// ブレークポイントの一覧表示
(gdb) i b
Num Type Disp Enb Address What
1 breakpoint keep y 0x00000000000011a4 in main at c_gdb.c:13
2 breakpoint keep y 0x0000000000001149 in func2 at c_gdb.c:3
// 実行
(gdb) run
Starting program: /home/koba/work/a.out
Breakpoint 1, main () at c_gdb.c:13
13 int main() {
// バックトレースの表示
(gdb) bt
#0 main () at c_gdb.c:13
// プログラムの続行
(gdb) continue
Continuing.
Breakpoint 2, func2 (x=0) at c_gdb.c:3
3 void func2(int x) {
// バックトレースの表示
(gdb) bt
#0 func2 (x=0) at c_gdb.c:3
#1 0x00005555555551a1 in func1 (a=5, b=10) at c_gdb.c:10
#2 0x00005555555551cd in main () at c_gdb.c:16
(gdb) continue
Continuing.
func2: y = 17
// デバックの正常終了
[Inferior 1 (process 3392) exited normally]
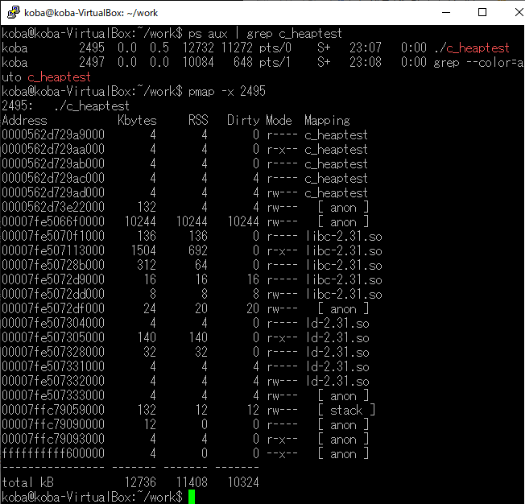
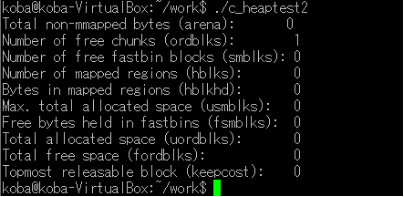
3.ヒープメモリの確認 (1)動的メモリのデバッグツール:Valgrind(ヴァルグリンド、GNU General Public License) Valgrindは、メモリリークや不正なメモリアクセスを検出するための動的解析ツールの一つです。Valgrindを使用してプログラムを実行すると、ヒープメモリの使用状況が詳細に報告されます。
#Valgrkoba@koba-VirtualBox:~/work$ sudo snap install valgrind --classic
valgrind 3.22.0 from Roger Light (ralight) installedindのインストール
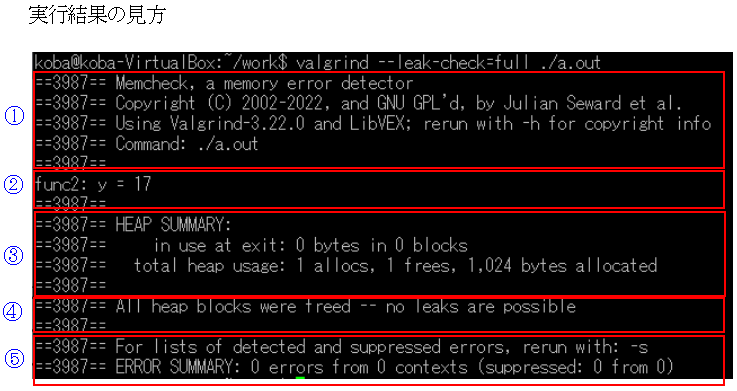
#valgrindの実行結果
koba@koba-VirtualBox:~/work$ valgrind --leak-check=full ./a.out
==3987== Memcheck, a memory error detector
==3987== Copyright (C) 2002-2022, and GNU GPL'd, by Julian Seward et al.
==3987== Using Valgrind-3.22.0 and LibVEX; rerun with -h for copyright info
==3987== Command: ./a.out
==3987==
func2: y = 17
==3987==
==3987== HEAP SUMMARY:
==3987== in use at exit: 0 bytes in 0 blocks
==3987== total heap usage: 1 allocs, 1 frees, 1,024 bytes allocated
==3987==
==3987== All heap blocks were freed -- no leaks are possible
==3987==
==3987== For lists of detected and suppressed errors, rerun with: -s
==3987== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
①Valgrindの概要 Memcheck:Valgrindの一部で、メモリエラーの検出を行います。 Copyright:Valgrindの著作権情報。 Version:使用しているValgrindのバージョン。 Command:実行されたコマンド(ここでは ./a.out )。 ②プログラムの出力 プログラム自体の出力でfunc2関数からの出力。 ③HEAP SUMMARY(ヒープの概要) ・in use at exit:プログラム終了時に使用中のメモリの量。ここでは、0バイトが0ブロックに使用されていることを示しています。つまり、全てのメモリが解放されています。 ・total heap usage:プログラムの実行中に行われたメモリ割り当て(allocs)と解放(frees)の総数、および割り当てられたメモリの総量。 ・1 allocs:1回のメモリ割り当てが行われた。 ・1 frees:1回のメモリ解放が行われた。 ・1,024 bytes allocated:合計で1,024バイトのメモリが割り当てられた。 ④メモリリークの確認 ・All heap blocks were freed:すべてのヒープメモリブロックが解放されたことを示します。 ・no leaks are possible:メモリリークがないことを意味します。 ⑤エラーの概要 ・0 errors from 0 contexts:検出されたエラーはゼロであることを示します。 ・suppressed: 0 from 0:抑制されたエラーはないことを示します。
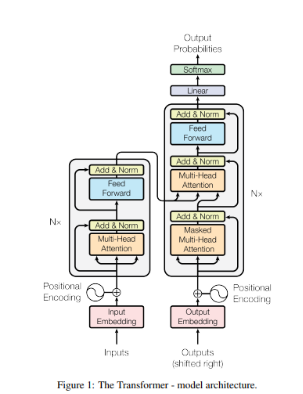
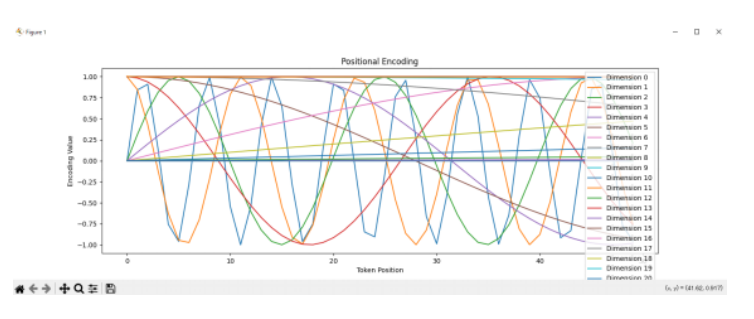
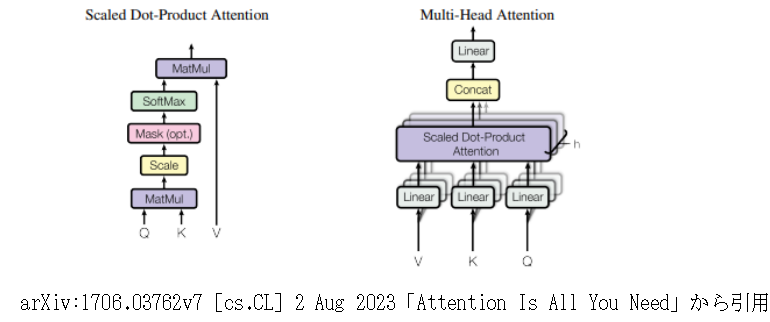
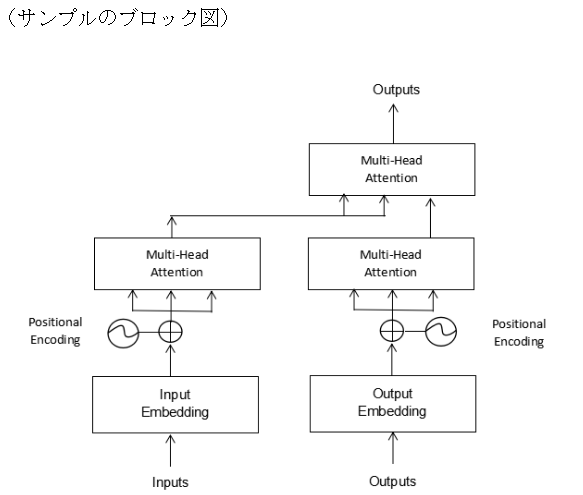
1.概要 トランスフォーマーの元となるアーキテクチャは、以下の論文で発表されました: Title: Attention Is All You Need Authors: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin Published in: NeurIPS 2017 (Conference on Neural Information Processing Systems) ChatGPTなどの自然言語処理、画像生成などモデルとして使用されて、主な特徴を以下に示します。
#include <stdio.h>
// 2 つの整数を引数として、その合計を返す関数
int add(int a, int b) {
return a + b;
}
int main() {
// 関数ポインタの宣言
int (*func_ptr)(int, int);
// 「add」関数のアドレスをポインタ変数に代入
func_ptr = &add;
// ポインタを介して関数を間接的に呼び出す
int result = (*func_ptr)(2, 3);
printf("The result is %d\n", result);
return 0;
}
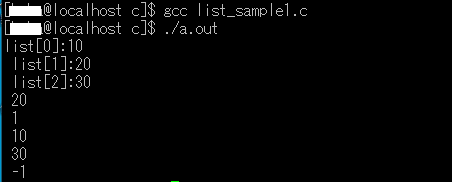
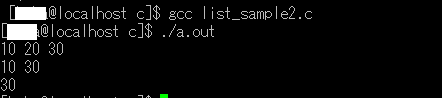
#include <stdio.h>
#define MAX_SIZE 100 // maximum size of the list
struct List {
int items[MAX_SIZE];
int size;
};
// initialize the list
void initList(struct List *list) {
list->size = 0;
}
// add an item to the list
void addItem(struct List *list, int item) {
if (list->size == MAX_SIZE) {
printf("List is full\n");
return;
}
list->items[list->size++] = item;
}
// remove an item from the list
void removeItem(struct List *list, int index) {
if (index < 0 || index >= list->size) {
printf("Invalid index\n");
return;
}
for (int i = index; i < list->size - 1; i++) {
list->items[i] = list->items[i+1];
}
list->size--;
}
// get an item from the list
int getItem(struct List *list, int index) {
if (index < 0 || index >= list->size) {
printf("Invalid index\n");
return -1;
}
return list->items[index];
}
// print the list
void printList(struct List *list) {
for (int i = 0; i < list->size; i++) {
printf("%d ", list->items[i]);
}
printf("\n");
}
int main(void){
struct List list;
initList(&list);
addItem(&list, 10);
addItem(&list, 20);
addItem(&list, 30);
printList(&list); // prints "10 20 30\n"
removeItem(&list, 1);
printList(&list); // prints "10 30\n"
printf("%d\n", getItem(&list, 1)); // prints "30\n"
return 0;
}